P 05q 1 05. The chi2pdf function can be used to calculate the chi-squared distribution for a sample space between 0 and 50 with 20 degrees of freedom.
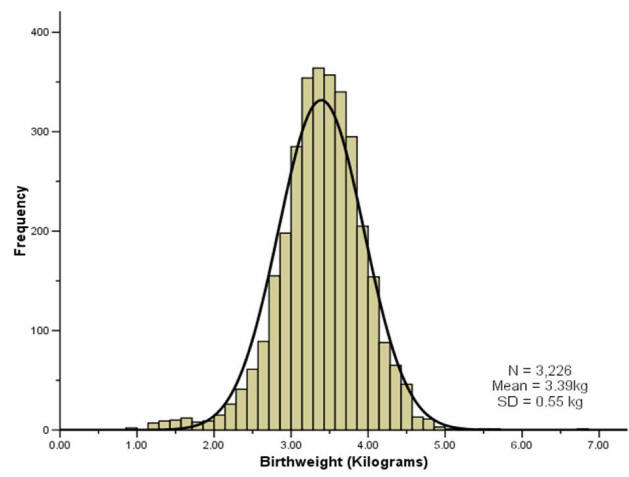
Standard Statistical Distributions E G Normal Poisson Binomial And Their Uses Health Knowledge
If your data follow the straight line on the graph the distribution fits your data.

. You can convert extreme data points into z scores that tell you how many standard deviations away they are from the mean. The normal distribution is an essential statistical concept as most of the random variables in finance follow such a curve. This confirms our graphical conclusion that the sample is compatible with a Weibull distribution.
Statistics dont just look at the data and calculate the average what statistics try to do is to find the original probability distribution from which the collected data originated. If the P-Value of the KS Test is larger than 005 we. Just follow the below 2 steps to create statistical distribution frequency of any set of values using excel.
How To Calculate Population DistributionTo calculate the population density you will divide the population by the size of the area. S1 samples of group 1. For a statistical test to be valid your sample size needs to be large enough to approximate the true distribution of the population being studied.
Statistical outlier detection. How to Identify the Distribution of Your Data. Example of Non-Normal Distributions.
Probability plots might be the best way to determine whether your data follow a particular distribution. If the observed data perfectly follow a normal distribution the value of the KS statistic will be 0. Assuming the test scores range from 0 to 100 you can define score bands like 102030405060708090100.
Statistical outlier detection involves applying statistical tests or procedures to identify extreme values. Around 68 of values are within 1 standard deviation from the mean. As a rule of thumb.
Next youll need to determine the degrees of freedom. Lower Range 65-353 545. The null hypothesis in this test is that the distribution of the ranks of each type of score ie reading writing and math are the same.
Around 997 of values are within 3 standard deviations from the mean. Start by looking at the left side of your degrees of freedom and find your variance. The formula for this is as follows.
Follow the flow chart and click on the links to find the most appropriate statistical analysis for your situation. The Kaggle Dataset used can be downloaded from here. Many datasets naturally fit a non-normal model-The number of accidents tends to fit a Poisson distribution-The Lifetimes of products usually fit a Weibull distribution.
Next segregate the samples in the form of a list and determine the mean of each sample. The P-Value is used to decide whether the difference is large enough to reject the null hypothesis. Degrees of freedom s1 s2 - 2.
So we know that there are 5050 possibilities of landing on either tails or heads. Thus in this example the probability of the successful results is written as p while the probability of the outcomes of failure is written as q which is calculated as 1 p. Next prepare the frequency distribution Frequency Distribution Frequency distribution.
If a value has a high enough or low enough z score it can be considered an outlier. Tests looking at data shape see also Data distribution. P a Z b P Z b P Z a explained in the section above Then express these as their respective probabilities under the standard normal distribution curve.
In order to calculate these probabilities we must integrate the pdf over the range a-b or 0-b respectively. S2 samples of group 2. Hence in this case.
Fit. First separate the terms as the difference between z-scores. Thus Population Density Number of PeopleLand Area.
Around 95 of values are within 2 standard deviations from the mean. Finally youll calculate the statistical significance using a t-table. Although the normal distribution takes centre part in statistics many processes follow non-normal distributions.
This handy tool allows you to easily compare how well your data fit 16. Recall that the sum squared values must be positive hence the need for a positive sample space. To determine which statistical test to use you need to know.
Also download the statistical distributions example workbook and play with it. Using Probability Plots to Identify the Distribution of Your Data. Define the bands for distribution.
We will use this test to determine if there is a difference in the reading writing and math scores. The empirical rule or the 68-95-997 rule tells you where most of your values lie in a normal distribution. P Z b P Z a Φ b Φ a.
KnowingApproximating the Datas probability distribution also helps us to use its statistical properties and attach confidence interval to the values it can take. SciPy provides the statschi2 module for calculating statistics for the chi-squared distribution. Once you do that you can learn things about the populationand you can create some cool-looking graphs.
To identify the distribution well go to Stat Quality Tools Individual Distribution Identification in Minitab. So 99 of the time the value of the distribution will be in the range as below Upper Range 65353 755. The probability density function or pdf is a function that is used to calculate the probability that a continuous random variable will be less than or equal to the value it is being calculated at.
Describing a sample of data descriptive statistics centrality dispersion replication see also Summary statistics. You can use square feet or meters if you ar. I also covered how to do that using Python and introduced various metrics to check the Goodness of fit.
Whether your data meets certain assumptions. The unit of land area should be square miles or square kilometers. First identify the distribution that your data follow.
The types of variables that youre dealing with. In the Probability Distribution Plot View Probability dialog Graph Probability Distribution Plot View Probability choose the binomial distribution enter 25 trials and an event probability of 002. Each tail will 992 495.
Go to the Shaded Area tab and choose X Value Right Tail and enter 2. Firstly find the count of the sample having a similar size of n from the bigger population of having the value of N.
A Gentle Introduction To Statistical Data Distributions

Basic Analytics Module For Sponsors Normal Distribution Change Management Statistical Process Control
Statistical Distribution Statistics Math Learning Mathematics Math Resources





0 Comments